不重复排名的排名

我最近第一次使用RANKEQ函数,并意识到任何相同的值将具有相同的秩。它会跳过你在排名数字中有多少重复,所以你可能有一个排名方案看起来像1,2,3,3,3,6,7,7,9,9。
这在某些情况下可能有用,但在其他情况下实际上是有问题的。假设我要搜索集合中的前10个值。我不会找到4、5、8或10的值。如果我想简单地绘制数据集中的前10个值,这当然会令人沮丧。
我创建了下面的公式来忽略重复项,并简单地将任何重复项的秩增加1。这意味着任何副本将对彼此具有任意的排名。
在这个公式中,“A”是被排序的列。
排名= RANKEQ ((电子邮件保护), a: a) + countif (a $1;(电子邮件保护), RANKEQ(@cell, A:A) = RANKEQ((电子邮件保护), a: a) - 1
希望这能帮助到一些人!
评论
-
 吉纳维芙P。 员工管理
吉纳维芙P。 员工管理感谢您与社区分享您的解决方案!
-
 杰夫瑞斯曼 ✭✭✭✭✭✭
杰夫瑞斯曼 ✭✭✭✭✭✭非常感谢您的配方!这是一个救命稻草。我将其作为基于多种标准获得排名的基础。我希望下面的建议可以补充到你的解决方案中,以帮助下一个遇到类似问题的人:
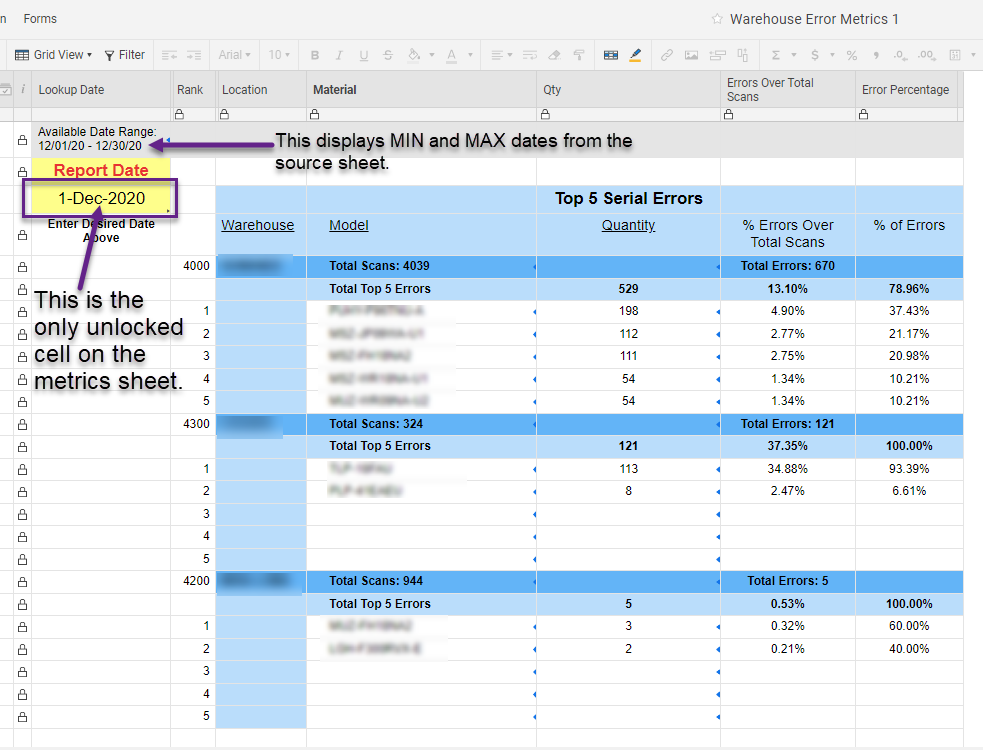
我有一个表格,每个月重新填充来自三个不同仓库的扫描错误数据,每个月的每一天。每行列出日期、仓库编号、型号以及记录的扫描错误数量。我需要能够找到每个仓库每天扫描错误最多的前5个模型。因此,2020年12月1日将有仓库4000的前5名,仓库4200的前5名和仓库4300的前5名。我需要能够在一个指标表上显示这些数据,用户在其中选择日期,系统显示每个仓库该日期的前5个数据。
我能够根据该标准获得每个仓库的每个日期的排名,但当然我有重复的排名。当我尝试您的公式时,试图将标准嵌入到COUNTIF内的RANKEQ公式中,一直返回一个#NESTED criteria错误。所以令人沮丧!
在我的数据表中,我有日期列(Date)、型号列(Material)、扫描错误列(Qty)、等级列(Rank)和一个仓库编号与基于日期列(whday)的年份的日期相连的列。whday列将仓库号和日期组合到一个字段中,以标识给定仓库在给定日期的所有行。我还有另一列,名为Number,它是一列升序数字,从1开始,一直到400(大约是给定月份的数据行数)。
= RANKEQ ((电子邮件保护)收集(数量:数量,[WH-Day]: [WH-Day], [WH-Day] @row), 0) +条件统计(数量:1美元(电子邮件保护)RANKEQ (@cell收集(数量:数量,[WH-Day]: [WH-Day], [WH-Day] @row), 0) = RANKEQ ((电子邮件保护)收集(数量:数量,[WH-Day]: [WH-Day], [WH-Day] @row), 0)) - 1这导致了#NESTED CRITERIA错误。我尝试了对标准的各种更改,得到了#UNPARSEABLE或#INVALID DATA TYPE。上面的各个部分都可以工作,直到我单独拥有整个COUNTIF部分,然后是嵌套的标准错误。
我最后做的是为这三个仓库中的每一个创建帮助表。我的源数据按日期升序排序,然后按仓库编号升序排序。对于给定的日期,每个仓库的行位于Number列的连续范围内。

在我的帮助表我有以下内容:
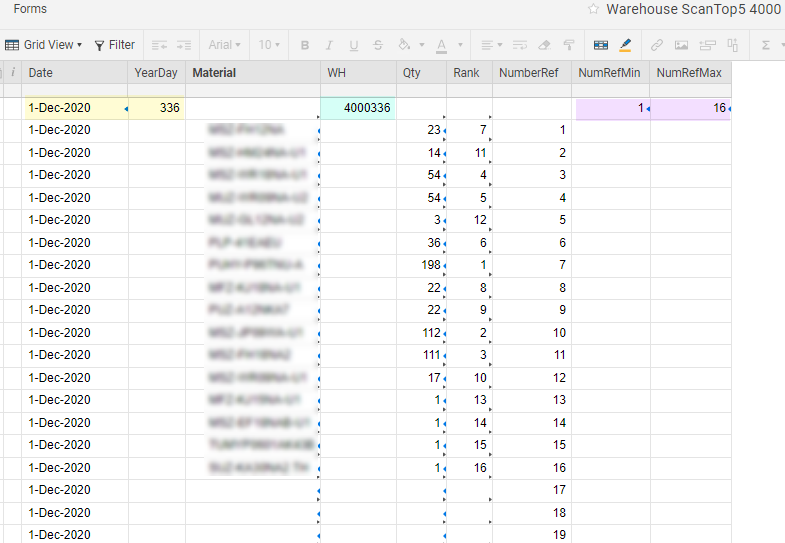
(日期1单元格链接从我的指标表(用户输入选择日期。)我得到了YearDay值(
=如果(YEARDAY ((电子邮件保护)) < 10, "00", if (yearday ()(电子邮件保护)) < 100, "0")) + yearday ((电子邮件保护)))和在WH列将仓库编号连接到YearDay值((加入(“4000”+ =价值(电子邮件保护))))使用MIN和MAX,我将WH值的开始编号和结束编号拉入NumRefMin和NumRefMax第1行的列:
=MIN(COLLECT({仓库扫描错误数据编号},{仓库扫描错误数据工作日}),(电子邮件保护)))我抓住材料的值。NumberRef值,前提是NumberRefIs <= toNumRefMax:
=如果((电子邮件保护)< VALUE(NumRefMax1 + 1), INDEX({仓库扫描错误数据表}),MATCH((电子邮件保护),{仓库扫描错误数据数},0),1),"")我得到了数量值使用相同的标准。使用IF可以避免在没有匹配值时出现#NO MATCH或其他错误。
一旦我有了材料和数量值,我可以使用普雷斯顿的公式得到我的排名,没有重复!同样,我使用IF来避免任何单元格中的错误值。
=如果((电子邮件保护)> 0,RANKEQ ((电子邮件保护),数量:数量)+ COUNTIF(数量$2:(电子邮件保护), RANKEQ(@cell, Qty:Qty) = RANKEQ((电子邮件保护), Qty:Qty)) - 1”、“)使用每个仓库单独的帮助表,我可以将数据拉到我的指标表中,从而为我提供所需的正确排名和值。用户选择一个有效的日期,点击保存,并在几秒钟内更新数据(在单元格更新时以蓝色闪烁)。
问候,
杰夫瑞斯曼,IT业务分析师及项目协调员,三菱电机特灵美国
链接:智能表功能帮助页面链接:Smartsheet公式错误信息
如果我的回答帮助解决了您的问题,请将其标记为接受,以便其他用户稍后可以找到它。谢谢!
-
普雷斯顿墨菲 ✭✭
哇! !我真的很高兴这有帮助!看来你真的把Smartsheet推向了极限,在这里做了一些高级的事情。谢谢分享!
-
有没有一种方法可以做到这一点,而不用在公式中使用@cell ?我正试图在一个工作表上纠正这一点,我需要能够转换为列公式和@cell不允许列公式?
-
林赛·惠特布莱德 ✭✭✭
没有重复的秩通常被称为“密集秩”。
我创建这个公式是为了得到密集的等级。它需要一个包含RANKEQ提供的“稀疏”秩的辅助公式。
从概念上讲,您使用RANKEQ创建稀疏秩,然后对稀疏秩进行排序以创建密集秩……然后将正确的稠密秩映射到每个稀疏秩。
在这个例子中,我将最小的值排到数字1的位置。
Helper列,我称之为“Item Sparse Rank”:
=IFERROR(RANKEQ([Item Value]@row, [Item Value]:[Item Value], 1), "")
把它写成列式
然后你做出你的密级:
=IFERROR(RANKEQ([Item Sparse Rank]@row, DISTINCT([Item Sparse Rank]:[Item Sparse Rank]), 1), "")
把它也变成列式。现在,我已经根据我自己的公式调整了这些公式,使其通用,所以如果它们实际上不起作用,请告诉我。
欢呼,
林赛
Smartsheet Lead @ InfoSpark
智能手机白金合作伙伴|www.infospark.com.au
-
 刘易斯水域 ✭✭✭
刘易斯水域 ✭✭✭嗨,林赛,
这给了我一个无效的数据类型在密集排名字段。什么好主意吗?
-
刘易斯水域 ✭✭✭
普雷斯顿的解决方案很好,但我真正想要的是副本有相同的排名和排名不被跳过。即
一个1
一个1
B2
C3
C3
D4
-
刘易斯水域 ✭✭✭
所以当我在稀疏秩上使用=value时,它似乎奏效了!



